SQL Commands
Joins
Inner Join
Left Join
Right Join
Full Join
Sql Primary Key
Sql Foreign Key
Sql Server Tips
More Select Statements
Stored Procedure
User Defined Functions
Difference between Stored Procedures and Functions
Performance Tuning of Stored Procedure
Sql Views
Triggers
What is an Index
Clustered Index
Non Clustered Index
Difference between Clustered Index and Non Clustered Index
Using temp table in Stored Procedure of SQL Server
Passing datatable as parameter to Stored Procedure in ADO.Net C#
Understanding SQL Server Non Clustered Index with an example
A non clustered index is stored seperately from the data table.For example,let us take our favourite book example,Here index of the book is maintained seperately and contents of the book is seperate. For example,if user needs to retrieve the email,location of the user named "Shiva".The database will first search username in the non clustered index table and fetch the actual record reference and use that to retrieve email and location of the user "shiva". Here database has to make two searches, first the non-clustered index and then in actual table. The non clustered index is slower for search operations.
Single Column Non Clustered index example:-
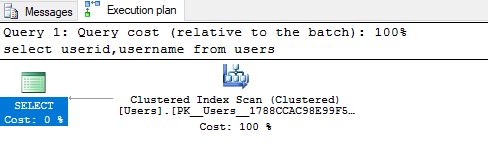
Here i am going to create non clustered index for single column in 'Users' table. Find users who is located in 'Malaysia'.
select userid,username from users where country='Malysia'
The estimated execution plan will scan the clustered index to find the row. This is because users table does not have an index for country column.
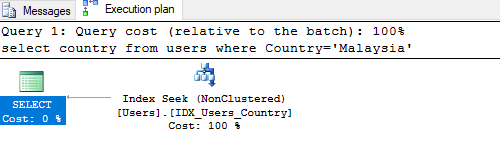
To retrieve the records faster ,we need to create new index named idx_users_country for the country column,
CREATE INDEX IDX_Users_Country
ON Users(country)
select country from users where Country='Malaysia'
Now if you display estimated execution plan of the above query,you will find uses of non clustered index 'idx_users_country'
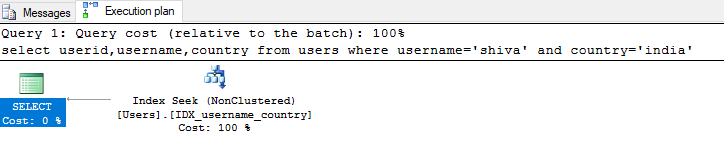
Multiple Column Non Clustered index example:-
Suppose we need to display the users with username='shiva' and country='india'
select userid,username,country from users where username='shiva' and country='india'
Execution plan result:
To fetch the results faster we can create a non clustered index on username and country
CREATE INDEX IDX_username_country
ON users(username,country)